1. What is click fraud?
Click fraud is usually defined as the act of purposely clicking on ads on pay-per-click programs with no interest in the target web site. Two types of fraud are usually mentioned:
- An advertiser clicking on competitor ads to deplete their ad spend budgets, with fraud frequently taking place early in the morning and through multiple distribution partners: AOL, Ask.com, MSN, Google, Yahoo, etc.
- A malicious distribution partner trying to increase its income, using clickbots or paid human beings to generate traffic that looks like genuine clicks.
While these are two important sources of non-converting traffic, there are many other sources of poor traffic. Some of them are sometimes referred to as invalid clicks rather than click fraud, but from the advertiser or publisher viewpoint, there is no difference. In this paper, we are considering all types of non billable or partially billable traffic, whether it is the result of fraud or not, whether there is or there is no intent to defraud, and whether there is or there is not a financial incentive to generate the traffic in question. These sources of undesirable traffic include:
- Accidental fraud: a home-made robot not designed for click fraud purposes, running loose, out of control, clicking on every links, possibly because of a design flaw. An example is a robot run by spammers harvesting email addresses. This robot was not designed for click fraud purposes, nevertheless ended up costing money to advertisers.
- Political activists: people with no financial incentives, but motivated by hate. This kind of clicking activity has been found against companies recruiting people in class action lawsuits, and results in artificial clicks and bogus conversions. It is a pernicious kind of click fraud because the victim thinks its PPC campaigns generate many leads, while in reality most of these leads (email addresses) are bogus.
- Disgruntled individuals: it could be an employee working for a PPC advertiser or a search engine, who was recently fired. Or it could be a publisher who believes to be unjustifiably banned.
- Unethical guys in the PPC community: small search engines trying to make their competitor look bad by generating unqualified clicks, or shareholder fraud.
- Organized criminals: spammers and other internet pirates used to run bots and viruses, who found that their devices could be programmed to generate click fraud. Terrorism funding comes in this category, and is investigated by the both FBI and the SEC.
- Hackers: many people have now access to home made web robots (the source code in Perl or Java is available for free). While it is easy to fabricate traffic with a robot, it is more complicated to emulate legitimate traffic as it requires spoofing thousands of ordinary IP addresses – not something any amateur can do well. Some individuals might find this as a challenge and generate high quality emulated traffic, just for the sake of it, with no financial incentives.
- Traditional media losing market share to PPC advertising have incentive to contribute to click fraud.
In this paper, we will be even more general by encompassing other sources of problems not generally labeled as click fraud, but sometimes referred to as invalid, non-billable, or low-quality clicks. This includes
- Impression fraud: impressions and clicks should always be considered jointly, not separately. This can be an issue for search engines, as their need to join very large databases and match users with both impressions and clicks. In some schemes, fraudulent impressions are generated to make a competitor’s CTR look low. Advanced schemes use good proxy servers (e.g. AOL) to hide the activity. When the CTR drops low enough, the competitor ad is not displayed anymore. This scheme is usually associated with self-clicking, a practice where an advertiser clicks on its own ads though proxy servers to improve its ranking, and thus improve its position in search result pages. This scheme targets both paid and organic traffic.
- Multiple clicks: while multiple clicks are not necessarily fraudulent, they end up either (i) costing lots of money to advertisers when they are billed at the full price or (ii) costing lots of money to publishers and search engines if only the first click is charged for. Another issue is how to accurately determine that two clicks – say five minute apart – are attached to the same user.
- Fictitious fraud: clicks that appear as fraudulent, but are never charged for. These clicks can be made up by unethical click fraud companies. Or they can be the result of testing campaigns, and we call them click noise. A typical example is Googlebot. While Google never charges for clicks originating from its Googlebot robot, other search engines that do not have the most updated list of Googlebot IP addresses might accidentally charge for these clicks. Another example of fictitious fraud further discussed in this paper is fictitious clicks. We explain what fictitious clicks are and how they can be detected.
2. A Black and White Universe, or is it Grey?
Our experience has shown that web traffic isn’t black or white, and that there is a whole range from low quality to great traffic. Also non converting traffic might not necessarily be bad, and in many cases can actually be very good. Lack of conversions might be due to poor ads, or poorly targeted ads. This raises two points:
- Traffic scoring: while as much as 5% of the traffic from any source can be easily and immediately identified as totally unbillable, with no chance of ever converting, a much larger portion of the traffic has generic quality issues – issues that are not specific to a particular advertiser. A traffic scoring approach (click or impression scoring) provides a much more actionable mechanism both for search engines interested in ranking distribution partners, and for advertisers refining their ad campaigns.
- A generic, universal scoring approach allows advertisers with limited or no ROI metrics to test new sources of traffic, knowing beforehand where the generically good traffic is, regardless of conversions. This can help advertisers substantially increase their reach and tap on new traffic sources as opposed to obtain very small ROI improvements from A/B testing. Some advertisers converting offline, victim of bogus conversions or interested in branding will find click scores most valuables.
A scoring approach can help search engines determine the optimum price for multiple clicks (here I mean true user-generated multiple clicks, not a double click that results from a technical glitch). By incorporating the score in their smart pricing algorithm, they can reduce the loss due to the simplified business rule “one click per ad per user per day”.
Search engine, publishers and advertisers can all win, as poor quality publishers can now be accepted in a network, but are priced correctly so that the advertiser still has a positive ROI. And good publisher experiencing drop in quality can have their commission lowered according to click scores, rather than being discontinued outright. When their traffic gets better, their commission increases accordingly, based on scores.
In order to make sense for search engines, a scoring system needs to be as generic as possible. The scores that we have developed meet this criterion. Our click scores have been designed to match the conversion rate distribution, using very generic conversions, taking into account bogus conversions, and based on patent-pending methodology to match a conversion with a click, through correct user identification. As everybody knows, an IP can have multiple users attached to it, and a single user can have multiple IP addresses within a two minute period. Cookies (particularly in server logs, less so in redirect logs) also have notorious flaws, and we do not rely on cookies when dealing with advertiser server log data.
We have designed scores based on click logs, relying – among other - on network topology metrics. We also have designed scores based on advertiser server logs, also relying on network topology metrics (distribution partners, unique browsers per IP cluster, etc.) and even on impression-to-click ratio and other search engine metrics, as we reconcile server logs with search engine reports to get the most accurate picture. Using search engine metrics to score advertiser traffic allow us to design good scores for search engine data, and the other way around as search engine scores are correlated with true conversions. It also makes us one of the very few third party traffic scoring company serving both sides equally well.
When dealing with advertiser server logs, the reconciliation process and the use of appropriate tags (e.g. Google’s gclid) whenever possible, allow us to not count clicks that are an artifact of browser technology. We have actually submitted a patent to eliminate what is called “fictitious clicks” by Google, and more generally, to eliminate clicks from clickbots.
Advertiser scores are designed to be a good indicator of conversion rate. Search engine scores use a combination of weights based both on expert knowledge and advertiser data. Score have been smoothed and standardized using the same methodology used for credit card scoring. The best quality assessment systems will rely on both our real-time and less granular scores, such as end-of-day.
The use of a smooth score, based on solid metrics, substantially reduce false positives. If a single rule is triggered, or even two rules are triggered, it might barely penalize the click. Also, if a rule is triggered by too many clicks or not correlated with true conversions, it is ignored. For instance, a rule formerly known as “double click” (with enough time between the two clicks) has been found to be a good indicator of conversion, and was changed from a rule into an anti-rule in our system, whenever the correlation is positive. A click with no external referral but otherwise normal will not be penalized, after score standardization.
3. Mathematical Model
The scoring methodology developed by Authenticlick is state-of-the art. It is based on almost 30 years of experience in auditing, statistics and fraud detection, both in real-time and on historical data. Several patents are currently pending.
It combines sophisticated cross-validation, design of experiments, linkage and unsupervised clustering to find new rules, machine learning, and the most advanced models ever used in scoring, with a parallel implementation and fast, robust algorithms to produce at once a large number of small overlapping decision trees. The clustering algorithm is a hybrid combination of unique decision-tree technology with a new type of PLS logistic stepwise regression to handle dozens of thousand highly redundant metrics. It provides meaningful regression coefficients computed in a very short amount of time, and efficiently handles interaction between rules.
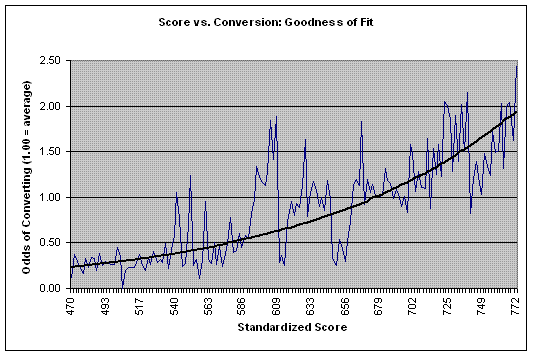
Some aspects of the methodology show limited similarities with ridge regression, tree bagging and tree boosting. Below we compare the efficiency of different systems to detect click fraud on highly realistic simulated data. The criterion for comparison is the mean square error, a metric that measures the fit between scored clicks and conversions:
- Scoring system with identical weights: 60% improvement over binary (fraud / non fraud) approach
- First-order PLS regression: 113% improvement over binary approach
- Full standard regression (not recommended as it provides highly unstable and non-interpretable results): 157% improvement over binary approach
- Second-order PLS regression: 197% improvement over binary approach, easy interpretation and robust, nearly parameter-free technique
Substantial additional improvement is achieved when the decision trees component is added to the mix. Improvement rates on real data are similar.
4. Bogus Conversions
The reason we elaborate a bit on bogus conversions is because its impact is worse than most people think. If not taken care of, it can make a fraud detection system seriously biased. Search engines that rely on pre-sales or non-sales conversions such as sign-up forms to assess traffic performance can be misled into thinking that some traffic is good when it actually is poor, and the other way around.
Usually, the advertiser is not willing to provide too much information to the search engine, and thus conversions are computed generally as a result of the advertising placing some JavaScript code or a clear gif on target conversion pages. The search engine is then able to track conversions on these pages. However, the search engine has no control on which “converting pages” the advertiser wants to track. Also, the search engine has no visibility on what is happening between the click and the conversion, or after the conversion. If the search engine has access to pre-sale data only, the risk for bogus conversions is high. We have actually noticed a significant increase in bogus conversions from some specific traffic segment.
Another issue with bogus conversions is when an advertiser (let’s call it an ad broker) purchases traffic upstream, and then acts as a search engine and distributes the traffic downstream to other advertisers. This business model is widespread. If the traffic upstream is artificial but results in many bogus conversions – a conversion being a click or lead delivered downstream – the ad broker does not see a drop in ROI. She might actually see an increase in ROI. Only the advertisers downstream start to complain. Once the problem starts being addressed, it might be too late and can cost the ad broker to loose clients. Had the ad broker used a scoring system such as ours, the bogus conversions would have been detected early, even if the ROI was unchanged.
This business flaw can be exploited by criminals running a network of distribution partners. Smart criminals will hit this type of “ad broker” advertisers harder: the criminals can generate bogus clicks to make money themselves, and as long as they generate a decent amount of bogus conversions, the victim is making money too and might not notice the scheme. If the conversions are tracked by the upstream search engine (where the traffic originates), the clicks might erroneously be considered very good.
5. A Few Misconceptions
It has been argued that the victims of click fraud are good publishers, not advertisers as advertisers automatically adjust their bids. However, this does not apply to advertisers lacking good conversion metrics (e.g. if conversion takes place offline) nor smaller advertisers who do not update bids and keywords in real time. It can actually lead advertisers to permanently eliminate whole traffic segments, and lack the good ROI when the fraud problem gets fixed on the network. On some 2nd-tier networks, impression fraud can lead an advertiser to be kicked out one day, without the ability to ever come back. Both the search engine and the advertiser lose in this case, and the one who wins is the bad guys now displaying cheesy, irrelevant ads on the network. The website user loses too as all good ads have been replaced with irrelevant material.
Another point that we sometimes hear is that 3rd party auditors do not have access to the right data. Again, not only auditors with large volume of traffic can track network flows just like search engines do, but in addition they have access to more comprehensive conversion data, and are better equipped to detect bogus conversions. In our case, we process search engine and advertiser data: large volumes of data in both cases. However, some auditing firms lacking statistical expertise and / or domain knowledge have had serious flaws in their counting methodology. These flaws have been highly publicized by Google, and overestimated. Due to “fictitious clicks”, 1000 clicks are on average reported as 1,400 clicks by some auditing firms, according to a well known source. The 400 extra “non-clicks” or “fictitious clicks” (they really never existed) are said to be from users clicking on the back button of their browser. It is well known that most visits are just one-page long, and content displayed by back-clicking with your browser is usually served by the browser cache, not by the advertiser server logs. Thus this 1,400 / 1,000 ratio does not make sense. We believe that the issue is of a different nature, such as counting all http requests associated with one page as the click tags are attached to all requests, depending on server configuration. It is also an issue that we have addressed long ago.
Auditing firms performing good quality reconciliation also have access to many metrics typically used by fraud detection systems for search engines: average ad position, bid, impression-to-click ratio, etc.
Finally, many systems to detect fraud are still essentially based on outlier detection and detecting shifts from average. Based on our experience in the credit card fraud industry, we know that most fraudsters try very hard to look as average as possible, avoiding expensive or cheap clicks, using the right distribution of user agents, generating a small random number of clicks per infected computer per day, except possibly for clicks going through AOL or other proxies. This type of fraud needs a truly multivariate approach, looking at billions of combinations of several carefully selected variables simultaneously, looking for statistical evidence in billions of tiny click segments, to unearth the more sophisticated fraud cases impacting large volume of clicks, possibly orchestrated by terrorists or large corrupt financial institutions rather than distribution partners.